
Clean data is the foundation of every successful AI initiative. AI starts with clean data, not complex models or cutting-edge algorithms. Even the most advanced machine learning systems will underperform when trained on inaccurate, inconsistent, or incomplete information. This is why many AI projects fail to move beyond experimentation, consuming time and resources while eroding stakeholder trust.
This playbook explains why AI starts with clean data and what it means to build datasets that are truly ready for AI and machine learning. You will learn how data quality directly impacts model accuracy, explainability, compliance, and long-term scalability, along with a practical framework for preparing and governing data effectively.
By applying the strategies in this guide, you will be equipped to reduce risk, accelerate AI adoption, and deliver reliable outcomes, positioning your organization to scale AI initiatives with confidence and lasting business value.
What Is AI-Ready Data?

AI-ready data is high-quality, well-structured, and specifically prepared to feed AI and machine learning systems with minimal risk of errors or bias.
For data to be considered AI-ready, it must meet these core criteria:
- Completeness: No critical missing values; enough data volume for robust model training.
- Consistency: Uniform formats, units, and codes across records—no contradictions or unintended duplicates.
- Accuracy: Free from errors, correctly represents real-world entities or events.
- Relevance: Contains all fields necessary for the target AI task (no irrelevant noise).
- Timeliness: Captures current or context-appropriate information.
Checklist: Is Your Data AI-Ready?
- All required fields are present (no essential missing data)
- Data types and formats are consistent (e.g., dates, numbers)
- No obvious errors or contradictory records
- Dataset reflects up-to-date, business-relevant information
- Duplicates and anomalies have been reviewed or removed
A common misconception is that “good enough” data suffices for AI. In reality, small quality issues compound rapidly in AI projects, resulting in unreliable models and unpredictable business outcomes.
Why Clean Data Matters: Business Cost & Risk of Dirty Data in AI
Dirty data in AI projects leads to costly failures, erodes trust, and can even expose organizations to regulatory risk.
Well-known industry sources highlight the challenge:
- According to Gartner, up to 85% of AI projects fail to deliver on their original objectives—often because of poor data quality.
- The Harvard Business Review reports that bad data costs companies trillions annually, factoring in wasted operational expense, failed projects, and reputational harm.
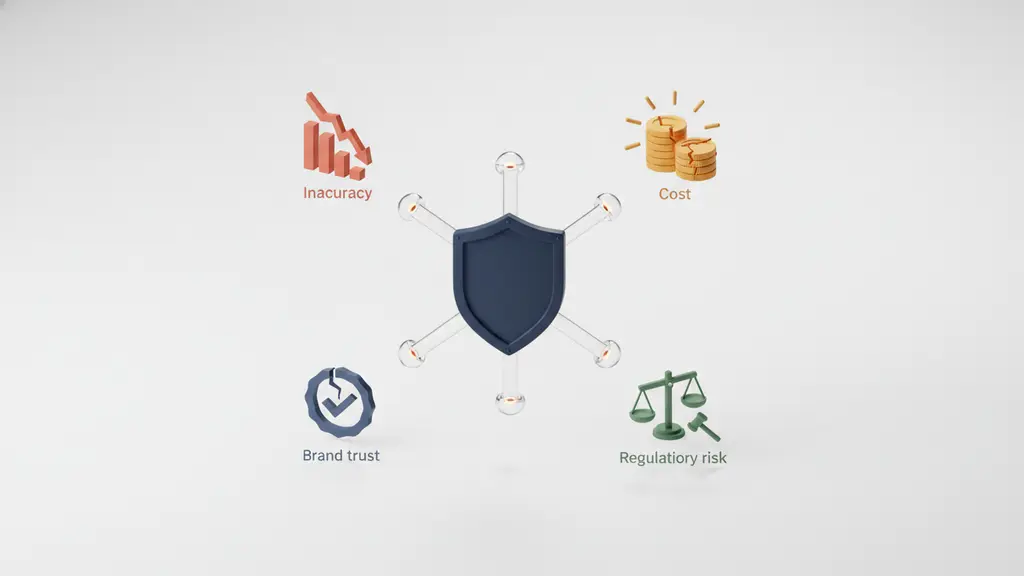
How Dirty Data Hurts AI Initiatives:
- Model Inaccuracy: Flawed training data results in biased or inaccurate AI outputs.
- Higher Costs: Significant time and money are wasted fixing problems late in the project lifecycle.
- Compliance Risk: Regulatory violations or privacy breaches can stem from uncontrolled or misused data.
- Brand Trust: Customers and internal stakeholders lose confidence in AI-driven decisions if results are unreliable.
Business Case:
Investing in data preparation might feel resource-intensive upfront. However, the cost of not investing—through unreliable insights, failed launches, or reputational loss—is far greater.
AI Starts With Clean Data: Key Steps to Prepare Data for AI

Preparing data for AI is a structured, multi-step process involving all aspects of quality, reliability, and governance. The following framework provides a high-level blueprint, detailing who owns each step and what success looks like.
AI Data Preparation: Five Essential Steps
- Data Audit & Profiling
- Data Cleaning, Structuring, and Enrichment
- Data Validation and De-Duplication
- Data Storage and Cataloging for AI Access
- Governance and Continuous Data Quality Monitoring
Ownership of each step often includes data engineers (technical execution), data managers (quality process), and data governance leads (policy and oversight).
Step 1 – Data Audit & Profiling: Building a Baseline
A thorough data audit and profiling exercise is the first step to understanding the quality, completeness, and structure of your existing data.
Key activities:
- Data Profiling: Use tools to scan datasets, highlighting missing values, inconsistent types, or common errors.
- Quality Metrics: Assess attributes like completeness, accuracy, uniqueness, and timeliness.
- Red Flags: Look for duplicate records, unusual value distributions, or non-standard formats.
Example checklist:
- Identify all data sources required for the AI model.
- Profile each data source for missing fields, data type mismatches, and summary statistics.
- Document initial findings and prioritize issues for cleaning.
Common tools for data profiling include OpenRefine, Talend Data Preparation, and built-in functions in languages like Python (with pandas-profiling).
Step 2 – Data Cleaning, Structuring, and Enrichment
Once you’ve audited your data, the bulk of effort goes into cleaning, structuring, and sometimes enriching it to meet AI standards.
Data cleaning tasks include:
- Removing or correcting erroneous records (e.g., negative ages, impossible values).
- Filling in missing values using domain logic or statistical imputation.
- Standardizing data formats (e.g., converting all dates to YYYY-MM-DD).
- Resolving inconsistent labeling, spelling variations, or encoding differences.
Enrichment strategies:
- Adding new, relevant information from internal databases, third-party sources, or external APIs.
- Merging disparate datasets for a more comprehensive training base.
Example scenario:
If customer purchase dates use different formats (MM/DD/YYYY, DD.MM.YYYY), standardize to one. If customer addresses lack postal codes, enrich them via a reputable external service.
The result: a dataset with fewer errors, less noise, and higher utility for AI modeling.
Step 3 – Data Validation and De-Duplication
After cleaning, data must be validated to ensure reliability—and freed from duplicates that could skew AI outcomes.
Validation approaches:
- Format Rules: Do fields fit specified types or regular expressions?
- Logic Rules: Do numerical ranges make sense (e.g., revenue must be non-negative)?
- Integrity Rules: Are relational constraints maintained (e.g., foreign key consistency)?
Validation may be automated with rules engines or performed manually for edge cases.
De-duplication routines:
- Use data matching algorithms or fuzzy logic to spot and merge/flag potential duplicates.
- Regularly review outputs for false positives or missed merges.
Common tools: Great Expectations for data validation, or fuzzy matching libraries in Python for de-duplication.
Step 4 – Data Storage and Cataloging for AI Access
Storing and cataloging data properly ensures that your cleaned and validated datasets are secure, accessible, and reusable across AI pipelines.
What is a data catalog?
A data catalog is a structured repository that documents metadata, lineage, and access permissions for each dataset.
Benefits:
- Improved collaboration—teams find and understand data faster.
- Enhanced compliance—access controls and lineage simplify audits.
- Supports versioning and traceability—critical for AI model audits.
Choosing a data catalog:
Options range from built-in cloud service catalogs (AWS Glue, Google Data Catalog) to enterprise solutions like Alation. Key features to look for include automated metadata extraction, search capabilities, access controls, and integration with your AI stack.
Step 5 – Governance and Continuous Data Quality Monitoring
Maintaining data quality is not a one-time effort—it relies on ongoing governance and monitoring to ensure your AI models remain reliable as data evolves.
Core governance roles:
- Data Stewards: Own data quality within a domain, monitor health, and resolve issues.
- Governance Leads: Set policies, oversee compliance, and guide continuous improvement.
Continuous monitoring includes:
- Automated data quality checks (KPIs: error rates, completeness, etc.).
- Regular audits and user feedback channels.
- Responsive change management when new data sources or business rules appear.
Case insight:
Organizations that embed data stewardship and quality KPIs into everyday workflows see far lower rates of AI-related incidents and compliance breaches.
What Are the Best Practices and Tools for Data Cleansing in AI?
Effective data preparation is rooted in tried-and-true best practices—and the right tools make these practices scalable and consistent.
Best Practices Checklist:
- Standardize formats and units before analysis
- Automate repetitive cleaning and validation steps wherever possible
- Document every transformation for auditability
- Validate all cleaned datasets prior to model training
- Schedule periodic reviews as data evolves
Comparison Table: Leading Data Cleansing Tools
| Tool | Key Features | Pricing Model | Strengths | Use Case Example |
|---|---|---|---|---|
| OpenRefine | Data profiling, cleaning | Free/Open Source | Quick, user-friendly, local | Small-medium datasets |
| Talend Data Prep | Clearing, enrichment, flows | Subscription | Automation, team features | Enterprise, complex data |
| Trifacta (Alteryx) | Visual pipelines, AI-suggested | Subscription | Usability, scalability | Big data, IT/BI teams |
| Great Expectations | Data validation/testing | Free/Open/Paid | Flexible validation | Ongoing QA, ML pipelines |
Note: Always review official documentation for feature updates and compatibility with your stack.
Automation vs. Manual:
Automate where possible (bulk standardization, validation), but retain expert review for edge cases and context-driven decisions.
How Can You Overcome Common Pitfalls and Organizational Resistance?
The biggest obstacles to clean data for AI aren’t always technical—they can also be organizational.
Common reasons teams skip or underinvest in data cleaning:
- Immediate project deadlines override quality concerns.
- Decision-makers underestimate data prep effort (“just clean it quickly”).
- Cleaning is siloed within IT, lacking cross-team buy-in.
Strategies for winning organizational support:
- Bring in project management and PMO leaders early—tie data quality to business outcomes and risk reduction.
- Use quick-win pilots to demonstrate the value of clean data (e.g., improved model accuracy in a single workflow).
- Communicate using visuals and case examples instead of technical jargon.
- Create cross-functional “data champion” groups to share responsibility.
Top Pitfalls & Solutions Table
| Pitfall | Impact | Solution |
|---|---|---|
| Over-cleaning | Loss of valuable signal | Focus cleaning on relevant fields only |
| Under-cleaning | Garbage in, garbage out | Use profiling to set cleaning priorities |
| Siloed ownership | Gaps or duplication of effort | Align roles, institute governance processes |
Expert Insight:
“Data preparation is a team sport. Involving end-users and business leaders in data quality standards pays dividends when model outputs go live.” — Data PMO Leader on Reddit
Case Example: How Enterprise Leaders Clean Data at Scale (Salesforce)
Enterprise leaders like Salesforce approach data cleaning as an ongoing, iterative process, starting small and scaling up with proven success.
Salesforce Approach:
- Start Small: Identify a single, contained use case (“boil a cup, not the ocean”).
- Iterate & Validate: Clean data in phases, validating improvements at each step.
- Toolset: Use a mix of internal tools and external solutions (e.g., Trifacta, Talend).
- Roles: Dedicated data stewards oversee business units; data governance team provides oversight.
Business Benefits:
- Improved model accuracy and faster AI deployment.
- Reduction in manual data correction, freeing up staff time.
- Enhanced ability to meet compliance and audit requirements.
Transferable Lessons:
- Don’t launch an organization-wide “cleaning initiative” without clear ownership and a pilot success story.
- Regularly update data governance protocols as your data and AI landscape evolve.
FAQ: Your Top Questions on AI Data Preparation, Answered
What is AI-ready data?
AI-ready data is complete, consistent, accurate, relevant, and accessible—meeting the quality standards needed for machine learning models to perform reliably.
Why is cleaning data important for machine learning?
Clean data prevents inaccurate, biased, or unpredictable model outcomes. Machine learning algorithms depend on trustworthy inputs to learn patterns and make decisions.
What are the key steps to prepare data for AI?
The core steps are: data audit/profiling, cleaning and structuring, validation and de-duplication, cataloging/storage, and continuous governance/monitoring.
Which tools are best for data cleaning and validation?
Popular tools include OpenRefine, Talend Data Preparation, Trifacta (Alteryx), and Great Expectations. Tool choice depends on data size, use case, and integration needs.
How does bad data affect AI project outcomes?
Bad data leads to inaccurate analyses, unreliable predictions, higher costs, and damaged trust in AI solutions—sometimes resulting in total project failure.
Who should own data prep for AI in an organization?
Data preparation should be shared across data engineers (process), data stewards (quality), and governance leads (policy), with business unit collaboration.
Can AI itself be used to clean data?
Yes, AI techniques can automate certain cleaning tasks (like anomaly detection), but human oversight and domain expertise are still essential for context and accuracy.
How to balance thorough cleaning with maintaining variability?
Clean only what’s necessary to remove error or noise—preserve legitimate outliers or natural variability where it holds signal for AI learning.
What are common pitfalls in AI data prep?
Pitfalls include over-cleaning (removing valuable diversity), under-cleaning (retaining error), siloed efforts, and lack of documentation.
How do you sustain quality over time?
Embed continuous monitoring, establish clear data stewardship roles, and regularly validate datasets as business needs and sources evolve.
Key Takeaways
- Clean, AI-ready data is non-negotiable for trustworthy and effective AI.
- A structured process, from audit to ongoing governance, prevents common failures.
- Leading data cleansing tools and automation shortcuts make the job feasible at scale.
- Organizational buy-in and documented best practices are just as important as technical steps.
- Continuous monitoring and stewardship ensure data quality—and AI ROI—over time.
FAQs
What is AI-ready data?
AI-ready data means it is complete, consistent, accurate, relevant, and properly formatted to support reliable machine learning or AI models.
Why is cleaning data important for machine learning?
Machine learning algorithms only perform as well as the data provided; cleaning eliminates errors, reduces bias, and increases model accuracy.
What are the key steps to prepare data for AI?
The key steps are auditing/profiling, cleaning/enriching, validating/de-duplicating, cataloging/storing, and continuous governance.
Which tools are best for data cleaning and validation?
Tools like OpenRefine, Talend, Trifacta, and Great Expectations are commonly used for their robust features and scalability.
How does bad data affect AI project outcomes?
Bad data can undermine AI initiatives, causing incorrect predictions, wasted resources, compliance issues, and eroded stakeholder trust.
Who should own the data preparation process for AI in an organization?
Data preparation is best managed collaboratively—data engineers, stewards, and governance leads all play critical roles.
Can AI itself be used to clean data?
Yes, AI can automate repetitive cleaning tasks, but human oversight is necessary to ensure contextual accuracy.
How to balance thorough data cleaning with maintaining data variability?
Focus cleaning effort on removing errors—preserve genuine outliers and natural differences that hold useful information.
What are common pitfalls when preparing data for AI?
Over-cleaning (removing helpful variation), under-cleaning, isolated or undocumented processes, and insufficient review all present risks.
How do you sustain data quality for AI projects over time?
Implement continuous monitoring, assign stewardship roles, and update preparations as your data sources, models, or regulations change.
This page was last edited on 2 February 2026, at 6:00 pm

Start a conversation with our team to solve complex challenges and move forward with confidence.









